Database Connection Pool이 등장 설명을 위해 JDBC에 대한 개념을 간단히 짚고 넘어가자.
JDBC
웹 애플리케이션은 정보 저장이 필요할 때 주로 데이터베이스(Database, 이하 DB)를 이용한다.
이를 위해 WAS는 애플리케이션이 DB로 접근할 수 있는 통일된 방법을 제공해야 하는데,
자바에서는 이러한 통일된 DB 접근을 위해 만든 표준이 바로 JDBC(Java Database Connectivity) 표준이다.
JDBC는 애플리케이션이 DB 커넥션을 사용하는 방법에 대해 기술하고 SQL 작업을 하기 위한 API를 제공한다.
JDBC 실행 과정

- DB 서버 접속을 위해 JDBC 드라이버를 로드한다.
- DB 접속 정보와 DriverManager.getConnection() Method를 통해 DB Connection 객체를 얻는다. (즉 데이터베이스와 연결한다.)
- Connection 객체로 부터 쿼리를 수행하기 위한 PreparedStatement 객체를 받는다.
- executeQuery를 수행하여 그 결과로 ResultSet 객체를 받아서 데이터를 처리한다.
- 처리가 완료되면 사용된 자원들을 close하여 반환한다.
자바 웹 애플리케이션은 요청에 따라 스레드를 생성하게 되고, 이 요청들의 대부분은 DB와의 연결이 필요한 요청들이다.
실제로 JDBC의 동작 과정에서 가장 많은 비용과 시간이 드는 부분은 바로 드라이버를 로드하고 커넥션 객체를 가져오는 부분인데,
만약 다수의 요청이 올 때마다 매번 새로 커넥션을 생성한다면 애플리케이션에 굉장한 부하가 올 것이다.
이런 비효율적인 부분들을 해결하기 위해 등장한 개념이 바로 Connection Pool이다.
Database Connection Pool (DBCP)
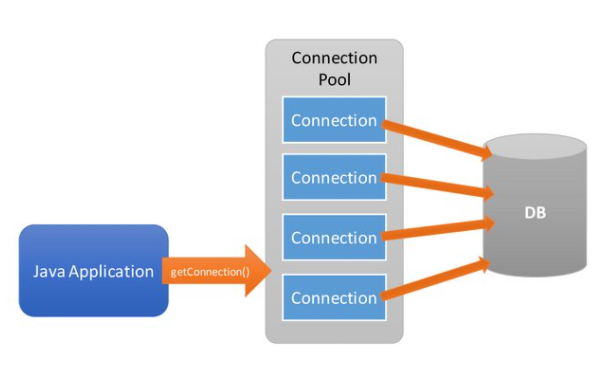
자바 웹 애플리케이션(WAS)에서 데이터베이스와 연결된 Connection을 미리 만들어 놓아 pool 속에 저장해 두고 있다가,
커넥션이 필요한 경우 Connection 객체를 Pool에서 쓰고 다시 Pool에 반환하는 프로그래밍 기법이다.
즉, 반복적으로 커넥션을 맺고 닫는 시간적, 비용적 부담을 줄이기 위해 미리 Connection 객체를 생성해두고 해당 Connection 객체를 관리하는 것이다.
또한 Connection Pool은 일정 관리할 커넥션 객체의 수를 지정해 생성하는데, 이 값이 너무 크다면 메모리 소모가 클 것이고, 또 너무 적다면 Connection 이 빈번히 발생할 경우 대기 시간이 길어지는 문제가 생기기 때문에 이 값을 잘 설정해야 한다.
Connection에 드는 비용이 정확히 뭔데?
참고: https://devkly.com/db/db-connection-pool/
커넥션 풀을 사용하는 이유가 결국 가장 많은 시간과 비용을 소모하는 커넥션을 맺고 닫는 일을 줄이기 위함이라한다.
그렇다면 커넥션을 생성하고 종료할 때마다 정확히 어떤 일이 발생하길래 많은 비용이 든다고 하나?
DBMS와의 통신은 TCP/IP로 이루어진다. TCP로 통신하는 프로그램들은 정확한 전송을 보장하기 위해 3-way handshaking 과정을 거치게 된다. 또한 연결을 종료할 때는 4-way handshaking 과정을 거치게 된다.
이 과정은 실제 물리적 회선을 거쳐서 이루어 져 많은 비용이 들게 된다.
또한 DBMS마다 클라이언트와 연결 과정이 조금씩 다른데, 각각 방식으로 클라이언트와 연결을 맺게되는지 알아보자.
Oracle
- 오라클 리스너 시작 (LISTEN)
- WAS에서의 커넥션 시도
- 데이터베이스에 연결할 때 필요한 정보를 오라클 클라이언트에게 전달(이 정보를 커넥션 디스크립터라고 부름)
- 오라클 클라이언트는 리스너와 클라이언트 사이에 소켓 생성
- 서버 프로세스의 생성
- 소켓을 생성하면 리스너가 SQL 처리를 해도 될 것 같지만, 한번 SQL 처리를 시작하면 해당 SQL 처리를 하느라 다른 처리를 할 수 없으므로...
- 서버 프로세스를 생성해서 SQL 처리를 즉시 인계
- 서버 프로세스 생성 과정
- 먼저 OS상에 프로세스 생성
- 서버 프로세스가 사용할 수 있는 공유 메모리를 확보
- 서버 프로세스용 전용 메모리(PGA)도 확보
- 서버 프로세스 생성 과정
- 리스너는 서버프로세스 생성이 끝나면 소켓을 서버 프로세스에 인계
즉 오라클은 매 커넥션을 생성할 때마다 매번 서버 프로세스를 OS 간에 생성도 해야한다.
MySQL
오라클은 하나의 쿼리마다 하나의 프로세스가 생기게되는 부담이 있었다.
MySQL은 단일 프로세스, 멀티 스레드이다. 오라클과는 달리 클라이언트를 담당할 프로세스가 아닌 스레드가 존재하게 된다.
(요청이 올 때마다 배정되는 포그라운드 스레드, 계속 돌고 있는 백그라운드 스레드가 있다.)
포그라운드 스레드
- 사용자가 요청한 쿼리 문장을 처리
- 스레드도 매번 생성하는 것은 부담이 크기에 스레드풀 개념을 사용
스레드 풀
- MySQL 커뮤니티 버전에서는 별도의 플러그인을 설치해야 사용이 가능
- 사용자가 DB 커넥션을 종료하면 해당 스레드는 스레드 풀로 돌아감
➕ DriverManager, DataSource
DriverManager
- DriverManager클래스는 인터페이스와 함께 작동 하여 Driver JDBC 클라이언트에서 사용할 수 있는 드라이버 세트를 관리
- 클라이언트가 연결을 요청하고 URL을 제공하면 URL DriverManager 을 인식하는 드라이버를 찾고 이를 사용하여 해당 데이터 소스에 연결하는 책임
- 이는 DBMS에 종속적일 수 밖에 없게 함
DataSource
- DriverManager의 발전된 형태로서 Connection 객체를 획득하기 위해 정보를 한단계 더 추상화
- DriverManager 와 데이터베이스간에 JNDI 기술을 이용하여 또하나의 레이어를 추가 하는 형태를 가짐으로써 Connection 객체를 획득하기 위한 오브젝트가 데이터베이스에 대한 절대 정보를 필요로 하는것을 피함
JNDI?
JNDI(Java Naming and Directory Interface)는 디렉터리 서비스에서 제공하는 데이터 및 객체를 발견(discover)하고 참고(lookup) 하기 위한 자바 API다.
JNDI는 일반적으로 다음의 용도로 쓰인다:
- 자바 애플리케이션을 외부 디렉터리 서비스에 연결 (예: 주소 데이터베이스 또는 LDAP 서버)
- 자바 애플릿이 호스팅 웹 컨테이너가 제공하는 구성 정보를 참고
출처 : 위키백과
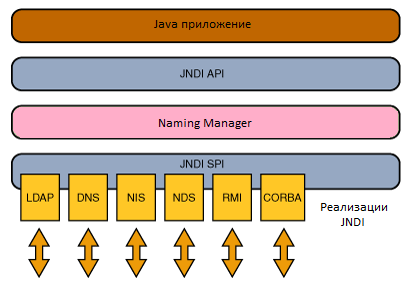
JDBC 를 사용하면, 먼저 Connection을 얻을때마다 드라이버를 DriverManager에 등록해야 했다.
하지만 JNDI 기법을 사용하면 서버 실행시 연동객체를 통해 DriverManager에 드라이버등록해놓고,
JDBC 사용할때 Connection을 얻는 부분에서 연동객체를 이름으로 찾아서(lookup) 사용할 수 있다.
즉 물리적인 데이터 소스를 논리적인 이름으로 연결시키는 작업이다.
Context ctx = new InitialContext();
DataSource ds = (DataSource) ctx.lookup(“java:comp/env/jdbc/SpringDS”);
return ds.getConnection();
// ds.getConnection() 내부에서 DriverManager.getConnection
DBPC 라이브러리 종류
자바에서 대표적인 DBCP 라이브러리는 Commons DBCP, Tomcat DBCP, HikariCP 정도가 있다.
Commons DBPC
- Apache Commons
- Apach에서 제공해주는 대표적 Connecrion Pool 라이브러리
속성값
| 속성 | 설명 |
| initialSize | BasicDataSource 클래스 생성 후 최초로 getConnection() 메서드를 호출할 때 커넥션 풀에 채워 넣을 커넥션 개수 |
| maxActive | 동시에 사용할 수 있는 최대 커넥션 개수(기본값: 8) |
| maxIdle | 커넥션 풀에 반납할 때 최대로 유지될 수 있는 커넥션 개수(기본값: 8) |
| minIdle | 최소한으로 유지할 커넥션 개수(기본값: 0) |

주의할 점
- maxActive >= initialSize
- 최대 커넥션 개수를 초기 생성할 커넥션 개수보다 크게 설정해야한다. 최초 생성 수가 최대 동시사용수보다 많으면 놀고 있는 커넥션이 생기게 된다.
- maxActive = maxIdle
- 만약 maxActive = 20, maxIdle = 10인 경우
- 10개의 커넥션이 모두 사용중일 때 커넥션이 하나 더 필요한 경우, maxActive가 여유가 있어 커넥션을 더 생성하고 반환하는데
- 반환하려해도 이미 maxIdle이 꽉 찼기 때문에 해당 커넥션을ㄴ 닫히게 된다.
- 계속해서 이런 상황이 반복된다면 커넥션 풀을 사용함에도, 제대로 사용하지 못하는 상황이 된다.
- maxIdle >= minIdle
Tomcat JDBC Connection Pool
- tomcat
- Tomcat에서 내장되어 사용하고 있으며 Apache Commons DBCP 라이브러리를 바탕으로 만들어짐
- Spring Boot 2.0 미만 버전의 default JDBC connection pool
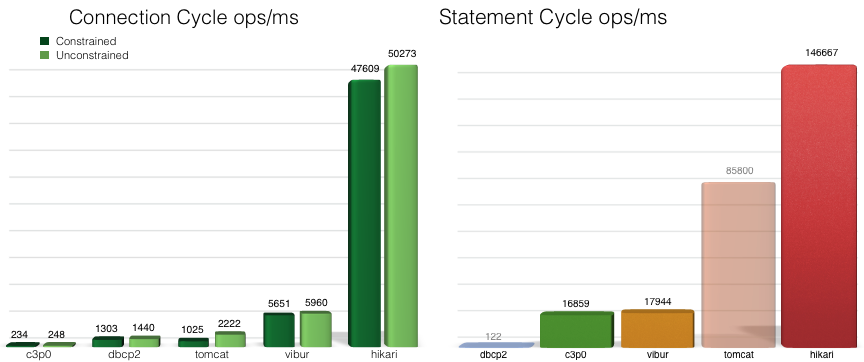
HikariCP
- HikariCP
- Spring Boot 2.0 이후 버전의 default JDBC connection pool
- Zero-Overhead를 특징으로 내세울 정도로 엄청 높은 성능을 강조
Spring에서 HikariCP 설정
application.properties를 활용해 다음과 같이 손쉽게 설정할 수 있다.
spring.datasource.hikari.username=username
spring.datasource.hikari.password=password
spring.datasource.hikari.maximum-pool-size=10
spring.datasource.hikari.connection-test-query=SELECT 1자주 사용되는 주요 설정
HikariCP의 설정이 굉장히 많기 때문에 공식 github를 보면 좋겠다.
auto-commit
- default : true
- 반환된 커넥션의 기본 auto commit 동작 제어
connection-timeout
- default: 30000 (30초)
- 클라이언트가 풀에서 커넥션을 얻어오기전까지 기다리는 최대 시간
- 허용가능한 wait time을 초과하면 SQLException
설정가능한 가장 작은 시간은 250ms
idle-timeout
- default : 600000 (10분)
- 커넥션이 pool에서 유휴 상태로 있을 수 있는 시간
- minimum-idle이 maximum-pool-size보다 작게 설정되어 있을 때만 적용됨
- 풀이 minimum-idle에 도달하면 해당 커넥션은 중단되지 않음
keep-alive-time
- default : 0 (비활성화)
- 데이터베이스 또는 네트워크 인프라에 의해 시간 초과되는 것을 방지하기 위해 HikariCP가 연결을 유지하려고 시도하는 빈도를 제어
- max-lifetime보다 작아야 함
- keepalive는 유휴 커넥션에서만 발생
- 커넥션이 keep-alive-time이 되면 풀에서 제거되고 ping된 다음 풀로 반환됨
- ping은JDBC4에서 isValid()나 connectionTestQuery 호출로 됨
- 최소로 하여 성능에 영향을 미치지 않을 정도로...
- 최소 허용값은 30000ms (30초)
max-lifetime
- default : 1800000 (30분)
- 커넥션 풀에서 살아있을 수 있는 커넥션의 최대 수명
- 사용중인 커넥션은 절대 제거되지않음 사용중이지 않을 때만 제거됨
pool 전체가아닌 커넥션 별로 적용이되는데 그 이유는 풀에서 대량으로 커넥션들이 제거되는 것을 방지하기 위함임
강력하게 설정해야하는 설정 값으로 데이터베이스나 인프라의 적용된 connection time limit보다 작아야함
0으로 설정하면 infinite lifetime이 적용됨
(idle-timeout설정 값에 따라 적용 idle-timeout값이 설정되어 있을 경우 0으로 설정해도 무한 lifetime 적용 안됨)
connection-test-query (default : none)
- JDBC4 드라이버를 지원한다면 이 옵션은 설정하지 않는 것을 추천
- JDBC4를 지원안하는 드라이버를 위한 옵션임(Connection.isValid() API)
- 커넥션 pool에서 커넥션을 획득하기전에 살아있는 커넥션인지 확인하기 위해 valid 쿼리를 던지는데 사용되는 쿼리
- JDBC4드라이버를 지원하지않는 환경에서 이 값을 설정하지 않는다면 error 로그를 발생
minimum-idle
- default : maximum-pool-size
- 최소 유휴 커넥션 수 제어
- 최적의 성능과 응답성을 요구한다면 이 값은 설정하지 않는게 좋음
- HikariCP가 최고의 성능을 내기위해 maximum-pool-size와 minimum-idle값을 같은 값으로 지정해서 커넥션풀의 크기를 고정하는 것을 권장
maximum-pool-size
- default: 10
- 유휴, 사용중 커넥션 모두를 포함해 풀에 유지시킬 수 있는 최대 커넥션 수
pool의 커넥션 수가 옵션 값에 도달하게 되고 사용가능한 유휴 연결이 없으면 getConnection() 호출이 connectionTimeout시간 초과되기 전에 최대 밀리초 동안 차단됨 - https://github.com/brettwooldridge/HikariCP/wiki/About-Pool-Sizing
교착 상태를 피하기 위한 풀 크기 계산은 매우 간단한 리소스 할당 공식입니다.
풀 크기 = T n x (C m - 1) + 1
여기서 T n 은 최대 스레드 수이고 C m 은 단일 스레드가 보유 하는 최대 동시 연결 수입니다.
pool-name
- 사용자가 pool의 이름을 지정
- 로깅이나 JMX management console에 표시되는 이름
참고자료
- https://technet.tmaxsoft.com/upload/download/online/jeus/pver-20140203-000001/server/chapter_datasource.html
- https://www.holaxprogramming.com/2013/01/10/devops-how-to-manage-dbcp/
- https://linked2ev.github.io/spring/2019/08/14/Spring-3-%EC%BB%A4%EB%84%A5%EC%85%98-%ED%92%80%EC%9D%B4%EB%9E%80/
- https://github.com/brettwooldridge/HikariCP
- https://devkly.com/db/db-connection-pool/
'데이터베이스' 카테고리의 다른 글
| [Real MySQL 8.0] 5장. 트랜잭션과 잠금 (0) | 2021.12.28 |
|---|---|
| 트랜잭션과 Spring의 선언적 트랜잭션에 대하여 (0) | 2021.11.20 |

