2021-04-10글
MVC와 Service
이번 미션에서 DB를 적용하면서 MVC 패턴에 추가로 Service 레이어를 도입하였다.
또한 DAO와 데이터 전달을 위한 DTO를 처음 사용했는데, DTO를 정리하고 DAO에 대해서도 새롭게 배운 부분이 많아 정리 ✍️

휴의 코멘트에 답변을 달다가 나의 코멘트 내용을 정정해주면서 같이 주신 참고자료가 있는데,
서비스 계층과 비즈니스 로직이라는 개념이 다르다는 것을 제대로 인지하지 못하고 있었던 것 같다.
때문에 휴가 주신 MVC 패턴과 Service 레이어에 관한 글을 읽고 간단히 정리해본다.
각 계층에 대한 개념은 조금씩 상이하니 일단 블로그 글은 서비스 계측과 비즈니스 로직에 대한
참고 정도만 한 수준에서 정리하고 다음 레벨에서 상세히 잡아가는 것이 좋겠다고 하셨다.
Layered Architecture
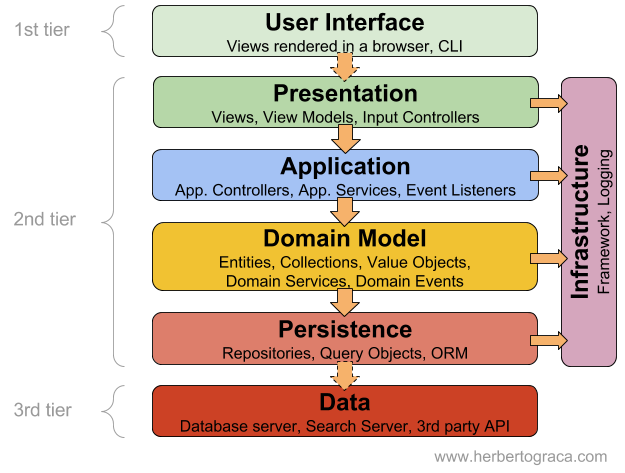
일반적으로 사용하는 레이어를 구분한다면 위와 같이 나눌 수 있다. MVC 패턴 또한 이 Layer를 잘 분리하기 위해 존재한다.
Layer 분리의 장점 ?
- 각 계층이 애플리케이션 내에서 특정 역할만을 수행하게 나눔으로, 비즈니스 요청을 충족하기 위해 수행해야하는 작업에 대한 추상화를 이룬다.
추상화가 잘 이루어진다면 서로 연결되어 있는 계층들이 독립적으로 계층에서 부품을 갈아끼우듯 변경할 수 있다. - 각 계층은 하위 계층에만 종속되고 상위 계층으로는 독립적으로 구성함으로, 위에서 아래로 떨어지는 간단한 구조로 만든다.
이로써 각 Layer를 넘나들면서 꼬여있는 의존 관계를 만들지 않는다.
Application Layer (= Service Layer)
도메인 모델을 묶어서 소프트웨어에서 사용 가능한 핵심 작업의 집합을 설정하는 계층이다.
보통 도메인 모델 하나만으로는 소프트웨어에서 처리하고자 하는 복잡한 작업을 할 수 없다.
때문에 여러 도메인 모델을 불러와 가공하고 비즈니스 로직을 호출해야하는데 이런 작업을 해주는 Layer가 필요하다.
여기서 여러 비즈니스 로직들을 의미있는 수준으로 묶어서 추상화하는 것이 바로 Application Layer이다.
만약 별도의 캡슐화가 필요하지 않은 경우에는 도메인 모델 그대로를 이 서비스로 만들 수 있다.
❓ 추상화가 필요한 이유
만약 UI, Gateway 같은 내부의 서비스 등 다양한 인터페이스로부터 작업을 요청 받는다면,
각 인터페이스의 종류와 목적이 다르더라도 이를 통해 공통적으로 사용하는 작업이 있을 것이다.
이 공통적인 작업이 각각에서 정의할 경우 중복이 발생하는데, 이를 Service Layer에서 인터페이스로 정의하여 중복을 제거한다.
즉, 핵심적인 API를 제공하는 계층이라고 할 수 있다.
중요한 것은 Service Layer는 추상화 계층으로 두고, 핵심 로직은 Business Layer에 두는 것이 옳다.
Business Layer (Domain Model)
데이터와 이에 관련된 비즈니스 로직인 메서드를 가지고 있는 객체이다.
Model 객체가 단순히 필드와 게터, 세터만을 가지고 있으면 DTO와 다를 것이 없다. (안티패턴)
즉, 도메인 모델에서 해당 데이터에 대한 비즈니스 로직을 가지고 있어야 한다.
DAO
미션이 merge된 후, 미처 질문하지 못한 것이 있어 휴에게 DM으로 질문을 남겼다.
현재 나의 로직에서는 chessGame 객체를 만들기 위해서 piece가 필요한데,
chessgame 테이블과 piece 테이블 각각에서 쿼리를 날려 데이터를 받아오고
이를 service에서 조합해(?) chessGame 객체를 만들고 있었다.

하지만 사실 쿼리를 다음과 같이 join을 사용해서 chessGame 객체를 만들기 위한 데이터를 얻어올 수 있었다.
SELECT turn, isFinish, color, name, position FROM chess_game cg inner join piece p WHERE cg.id = p.chessGameId;사실 이렇게 join을 통해서 얻어오려 했지만, dao를 테이블 별로 만들었더니 이 쿼리를 어디서 수행해야할지 판단할 수 없었다.
만약 chessGameDao에서 수행한다 하더라도 여기서piece 객체를 만드는 것도 아이러니하다고 생각도 들었다.
때문에 이렇게 DB에서 받은 결과를 어디에서 조합해야하는가에 대한 질문을 남겼다.
휴의 답변으로 Repository에 대한 것이 언급되었는데,
사실 이 질문 전에도 크루들과 Repository가 도대체 무엇인가에 대해서 토론했었다.
휴의 답변과 보내주신 참고 링크 덕분에 Repository가 어떤 역할을 하는 것인지 명확히 파악할 수 있었다.
DAO와 Reposotory의 차이점
DAO
- DAO 인터페이스는 DB의 CRUD 쿼리와 1:1 매칭되는 세밀한 단위의 오퍼레이션을 제공한다.
- 테이블 별로 하나의 DAO를 만든다.
- RANSACTION SCRIPT 패턴과 함께 사용된다.
- Persistence Layer에 속한다.
Repository
- Repository는 다수의 DAO를 호출하는 방식으로 구성된다.
- Repository에서 제공하는 한 오퍼레이션이 DAO의 여러 오퍼레이션에 맵핑되는 것이 일반적이다.
- DOMAIN MDOEL 패턴과 함께 사용된다.
- Domain Layer에 속한다.
- 객체 컬렉션 처리에 관한 책임만을 가지고 있다. 외부 시스템과의 상호작용은 별도의 Service가 담당한다.
따라서 현재 나의 질문 같은 경우는 Repository를 통해 ChessGameDao와 PieceDao로부터
가져온 데이터에 대한 집합 처리를 함으로 해결할 수 있다.
이 둘의 차이에 대해서는 지금 단계에서 이정도로 잡고 가자 !
'우아한테크코스 > 미션 정리' 카테고리의 다른 글
| Level2. atdd-subway-map 정리 (0) | 2021.08.06 |
|---|---|
| Level2. jwp-chess 정리 (0) | 2021.08.06 |
| [코드리뷰 정리] Level 1. 체스 미션 - JDBC (0) | 2021.08.06 |
| [코드리뷰 정리] Level 1. 체스 미션 -DTO (0) | 2021.08.06 |
| [코드 리뷰 정리] Level 1. 블랙잭 (1) | 2021.08.06 |



