1, 2 단계 - HTTP 서버 구현하기 & 리팩터링
HTTP
- HTTP 메시지는 ASCII로 인코딩된 텍스트 정보이며 여러 줄로 되어 있음
- HTTP 프로토콜 초기 버전과 HTTP/1.1에서는 클라이언트와 서버 사이의 연결을 통해 공개적으로 전달되었음
- 사람이 읽을 수 있었던 메시지는 HTTP/2에서는 최적화와 성능 향상을 위해 HTTP 프레임으로 나누어짐
- HTTP 메시지는 주로 소프트웨어, 브라우저, 프록시, 또는 웹 서버가 작성
HTTP Request 구조
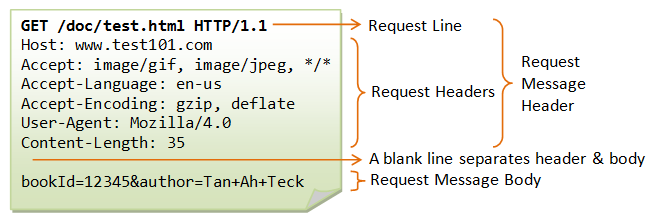

요청 메시지는 다음과 같은 메시지로 날아온다.
GET /index.html HTTP/1.1
Host: localhost:8080
Connection: keep-alive
Accept: */*먼저 내가 미션에서 만든 HTTP Request 객체의 구조는 다음과 같다.
public class HttpRequest {
private RequestLine requestLine;
private RequestHeaders headers;
private RequestBody body;
// ...Request Line
참고로 MDN에서는 시작줄(Start Line)이라고 명시되어 있다.
미션에서 만든 Request Line의 구조는 다음과 같다.
public class RequestLine {
private static final Logger log = LoggerFactory.getLogger(RequestLine.class);
private HttpMethod method;
private String path;
private Map<String, String> queryParams;
private String protocol;
// ...
}
실제 Request Line는 다음과 같은 구성으로 이루어져 있다.
Method
GET, PUT, POST 등을 사용해 서버가 수행해야 할 동작을 나타낸다.
미션에서는 다음과 같은 Enum을 만들어 이를 관리했다.
public enum HttpMethod {
GET, HEAD, POST, PUT, DELETE, CONNECT, OPTIONS, PATCH;
public static HttpMethod of(String method) throws IllegalStateException {
return Arrays.stream(HttpMethod.values())
.filter(httpMethod -> httpMethod.name().equalsIgnoreCase(method))
.findAny().orElseThrow(() -> new IllegalStateException("해당하는 HTTP 메서드를 찾을 수 없습니다."));
}
public boolean isGet() {
return this == GET;
}
public boolean isPost() {
return this == POST;
}
}Path
URL을 나타낸다. '?' 뒤에 쿼리 스트링을 붙여올 수도 있다.
미션에서는 path와 '?'가 있을 시 쿼리 스트링을 파싱해 Map에 저장하도록 했다.
try {
String[] tokens = splitByBlank(line);
this.method = HttpMethod.of(tokens[0]);
String uri = tokens[1];
if (uri.contains("?")) {
final int index = uri.indexOf("?");
this.path = uri.substring(0, index);
this.queryParams = extractQueryParams(uri.substring(index + 1));
} else {
path = uri;
}
this.protocol = tokens[2];
} catch (IllegalStateException exception) {
log.error("Exception invalid http request", exception);
}Version of Protocol
응답 메시지에서 써야 할 HTTP 버전을 알려준다.
Request Headers
헤더에는 대소문자 구분없는 문자열 다음에 콜론 ':'이 붙는다.
그 뒤에 오는 값은 헤더에 따라 달라진다. (key-value 형식)
각각은 한 줄로 구성된다.
미션에서는 이를 HashMap으로 관리하였다.
Request Body
요청의 마지막 부분에 들어간다.
모든 요청에 본문이 필수는 아니고 대개 GET, HEAD, DELETE , OPTIONS 와 같은 메서드는 본문이 필요 없다.
미션에서는 일단 단순 String 을 가지고 있는 객체로 만들었는데, 추후 Json 데이터가 들어올 시 이를 관리하면 좀 더 역할이 분명해질 것이라 생각한다.
미션 같은 경우는 login시 다음과 같은 요청이 날아온다.
POST /register HTTP/1.1
Host: localhost:8080
Connection: keep-alive
Content-Length: 80
Content-Type: application/x-www-form-urlencoded
Accept: */*
account=gugu&password=password&email=mazzi%40woowahan.com여기서 Content-Length가 요청 바디의 길이이기 때문에 이를 통해 버퍼를 생성해주어 body를 읽었다.
(사실 이부분을 놓치고 지나가서 request 바디 제대로 못읽어 꽤 헤맸다 ㅎ)
int contentLength = Integer.parseInt(httpRequestHeaders.get("Content-Length"));
char[] buffer = new char[contentLength];
reader.read(buffer, 0, contentLength);
String requestBody = new String(buffer);
HTTP Response 구조
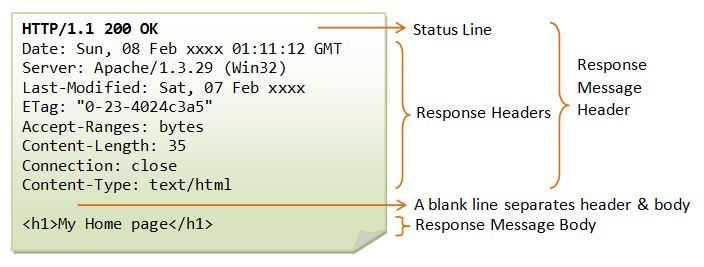
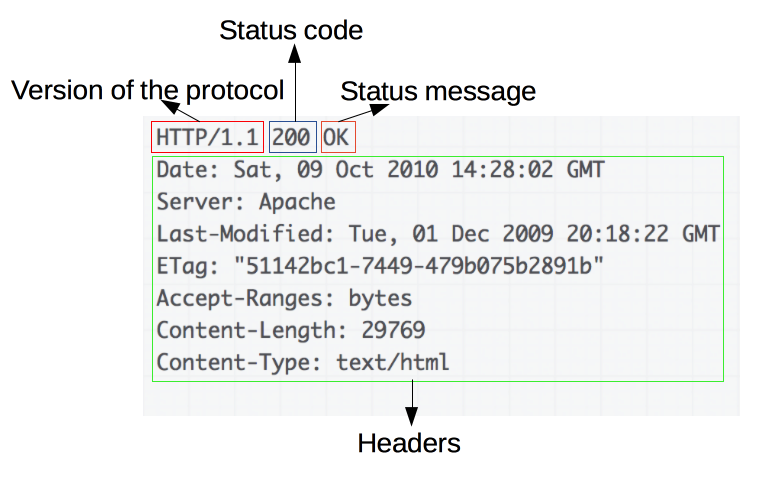
응답은 다음과 같은 메시지로 날아온다. 아래의 경우는 Redirect 응답이라 바디가 없다.
HTTP/1.1 302 Found
Location: http://localhost:8080/401.htmlStatus Line
미션에서 만든 Response Line의 구조는 다음과 같다.
public class StatusLine {
private final String protocol;
private final String statusCode;
private final String statusMessage;
// ...
}Version of Protocol
보통 HTTP/1.1
이다. 미션에서도 이로 명시해주었다.
Status Code & Status Message
요청의 성공 여부 등을 나타낸다.
미션에서는 상태코드에 대해 다음과 같이 코드와 메시지를 Enum으로 관리했다.
public enum StatusCode {
OK("OK", "200"),
FOUND("Found", "302"),
NOT_FOUND("Not Found", "404"),
UNAUTHORIZED("Unauthorized", "401");
// ...
}Response Headers
헤더에는 대소문자 구분없는 문자열 다음에 콜론 ':'이 붙는다.
그 뒤에 오는 값은 헤더에 따라 달라진다. (key-value 형식)
각각은 한 줄로 구성된다.
미션에서는 이를 LinkedHashMap으로 관리하였다.
Response Body
응답의 마지막 부분에 들어간다.
모든 응답에 본문이 필수는 아니고 대개 201, 204 와 같은 상태 코드는 본문이 필요 없다.
미션에서는 일단 단순 String 을 가지고 있는 객체로 만들었는데, 추후 Json 형태로 응답 바디를 줄 시 이를 관리하면 좀 더 역할이 분명해질 것이라 생각한다.
응답을 할 시 outputStream에 해당 응답 객체를 써야한다.
다음과 같이 response 객체 내에서 각각의(statusLine, statusCode 등...) byte를 가져와 byte를 쓰도록 구현했다.
public void write(OutputStream outputStream) {
try {
if (body == null) {
writeWithoutBody(outputStream);
} else {
writeWithBody(outputStream);
}
} catch (IOException exception) {
log.error("Exception output stream", exception);
}
}
private void writeWithoutBody(OutputStream outputStream) throws IOException {
outputStream.write(statusLine.getByte());
outputStream.write(headers.getByte());
outputStream.flush();
}HTTP 요청 / 응답 객체를 만들고 정리하는데 참고한 글
미션에서 진행한 HTTP 서버의 구조
HTTP 객체는 위와 같은 구조를 따라하려고 노력했다.
맨 처음 주어진 코드에서 RequestHandler에서 모든 요청에 대한 처리를 구현하려다 보니 너무 비대해지는 클래스를 마주하게 되었다.
그러다 자연스럽게 레벨 2쯤에 들었던 김영한님의 Spring MVC 기초 강의를 떠올리게 되었고 그 때 구현한 FrontendController 패턴을 떠올려 보았다.
일단 이번 미션에서 진행한 구조는 다음과 같다.
FrontController
public FrontController(Socket connection) {
this.connection = Objects.requireNonNull(connection);
controllerMap.put("/", new IndexController());
controllerMap.put("/login", new LoginController(new UserService()));
controllerMap.put("/register", new RegisterController(new UserService()));
}
원래 뼈대 코드의 명은 RequestHandler였는데, 네이밍을 변경했다.
현재 FrontController가 controllerMap을 가지고 있고 url을 key로 컨트롤러들을 관리하고 있다.
핸들러 맵핑 객체로 분리할 수 있을 것 같지만, 일단 시간도 그렇고 추후 리팩토링 단계에서 반영할 듯 하다.
이 맵에 있는 컨트롤러들은 각기 다른 처리를 진행하지만, 공통점이 있다면 결국 GET, POST 등 HTTP 요청 메서드에 따라 처리를 한다는 것이다.
때문에 Controller 인터페이스를 만들고 이를 구현한 추상 컨트롤러를 만들어 모든 컨트롤러들이 이를 상속받도록 했다.
public interface Controller {
void process(HttpRequest request, HttpResponse response);
}
public abstract class AbstractController implements Controller {
@Override
public void process(HttpRequest request, HttpResponse response) {
if (request.isGet()) {
doGet(request, response);
}
if (request.isPost()) {
doPost(request, response);
}
}
protected void doGet(HttpRequest request, HttpResponse response) {
}
protected void doPost(HttpRequest request, HttpResponse response) {
}
}실행
@Override
public void run() {
log.debug("New Client Connect! Connected IP : {}, Port : {}", connection.getInetAddress(), connection.getPort());
try (final InputStream inputStream = connection.getInputStream();
final BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
final OutputStream outputStream = connection.getOutputStream()) {
HttpRequest request = new HttpRequest(reader);
HttpResponse response = new HttpResponse();
String uri = request.getPath();
Controller controller = controllerMap.getOrDefault(uri, new DefaultController());
controller.process(request, response);
response.write(outputStream);
} catch (IOException exception) {
log.error("Exception stream", exception);
} finally {
close();
}
}실행시, 즉 요청이 들어오면 요청과 응답 객체를 생성한다.
요청 객체는 ouputStream을 통해 그 안에서 요청을 읽고 생성한다.
이후 요청에서 url에 해당하는 path를 얻어온다.
controllerMap에서 해당 pah와 맵핑되는 컨트롤러를 찾아오는데, 찾을 수 없다면 DefaultController를 내뱉는다.
이 컨트롤러의 역할은 스프링 DefaultServlet에서 착안해왔다.
DefaultServlet
정적 리소스와 디렉토리 목록(디렉토리 목록이 활성화된 경우)을 제공하는 서블릿이다.
이 DefaultServlet는 url에 맵핑된 서블릿의 요청을 가로채지 않기 위해 가장 낮은 우선순위를 가지게 된다.
조금 TMI를 말하자면 스프링에서 이 DefaultServlet을 커스텀 할 수도 있다는데, 지금 상황에서는 필요한 개념은 아니니 스킵.
실제로 DefaultServlet을 까보면 다른 서블릿과 동일하게 Get의 요청에 대한 처리하는 코드가 있다.


Get 요청에 대해 serveResource() 메서드로 정적 자원을 처리하는 코드를 볼 수 있다.
실제로 나도 DefaultController의 doGet 메서드에서 serveResource 메서드로 처리하고 싶었지만,
사실 지금 구조에서는 response.forward() 한줄 뿐이라 기각 시켰다.
참고자료
request 객체에서 reader를 통해 요청을 읽는 것과 같이 response 객체에서 자기 응답을 write하는 것이 더 역할이 명확하다고 느껴졌다.
그런데 지금와 생각해보니 현재 response 객체 내에서 forward, redirect 등 응답을 처리하는데,
외부에서 write를 호출하기 보다 응답 객체 내부에서 write를 하는 방법도 있겠구나 싶다.
Response ➕ forward와 redirect의 차이
자원 응답 - responseOk
public void responseOk(String uri) {
try {
URL resource = findResource(uri);
String content = readContent(resource);
if (content == null) {
responseNotFound();
return;
}
setStatusLine(StatusCode.OK);
this.headers.setContentType(ContentType.findByUri(uri));
this.headers.setContentLength(content.getBytes(StandardCharsets.UTF_8).length);
this.body = new ResponseBody(content);
} catch (IOException exception) {
log.error("Exception input stream", exception);
}
}사실 처음에는 무지성으로 html을 반환하니 forward라는 메서드명을 사용했다.
어떤 요청을 처리하고 이에 대해 html 페이지로 내부에서 이동하니까 이게 맞는거 아니야? 이렇게 생각했는데
다시 돌아보니 지금 코드에서는 단순한 get 요청에 대한 자원 응답 뿐이더라. (잘 이해한건진 모르겠다 ㅎ)
responseOk가 현재로써는 더 맞는 메서드명이라 생각했기에 변경했다.
forward에 대한 키워드를 좀 더 공부해보고 아래에 정리해보았다.
redirect
public void redirect(String redirectUrl) {
setStatusLine(StatusCode.FOUND);
this.headers.setLocation(redirectUrl);
}헤더에 location을 담아 이곳으로 이동하라고 명령을 내린다.
이 때의 상태 코드는 302이다.
forward vs redirect
그러면 이 둘의 차이는 무엇이냐... 물어본다면
Forward
요청과 응답이 한번만 이루어지며, 다음과 같은 흐름을 가진다.
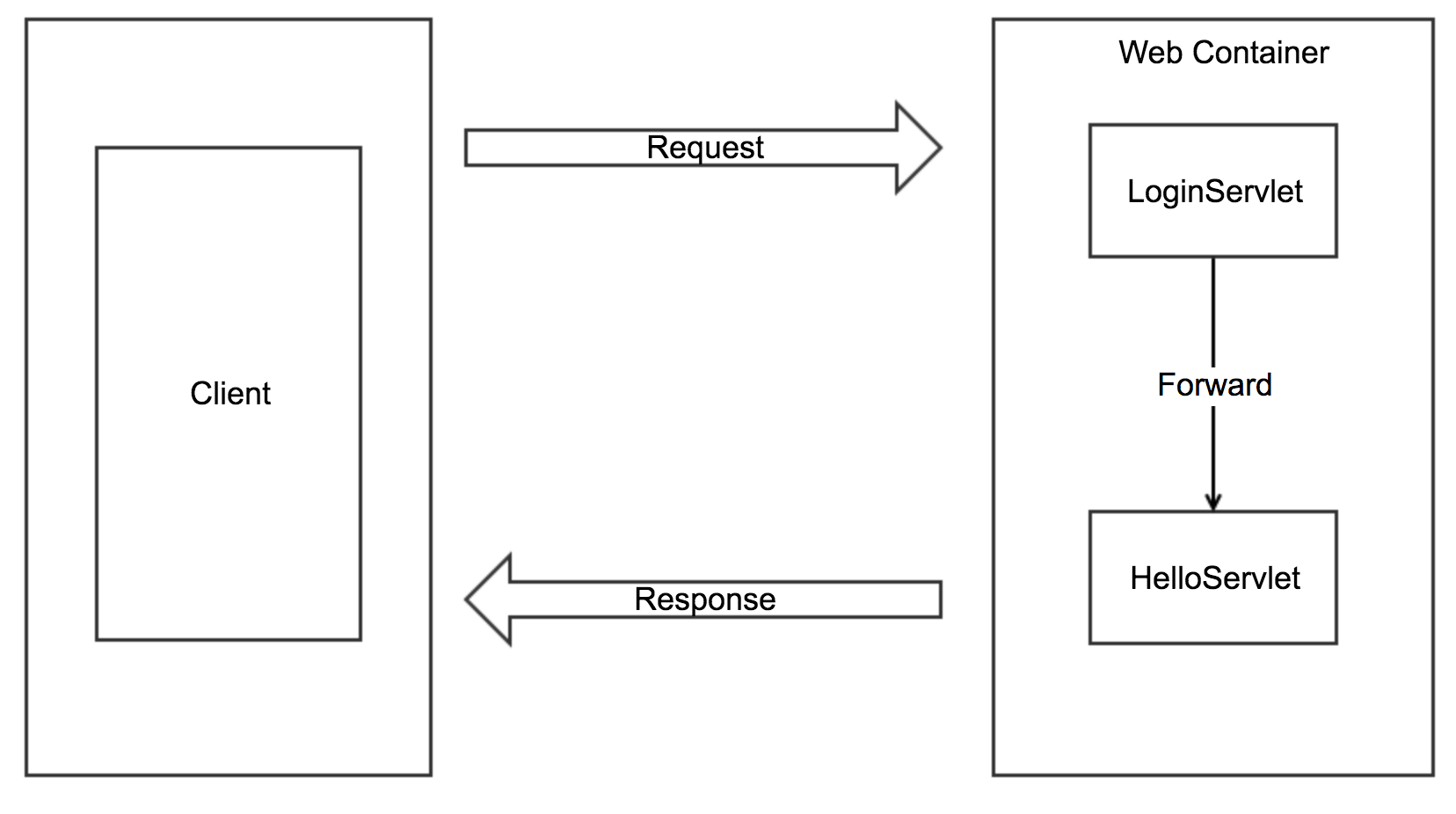
- 클라이언트가 서버에 요청
- 서버는 Web Container(Tomcat, Jboss등)에 의해 LoginServlet에서 HelloServlet로 forward
- 이때 객체 정보는 Request Scope, Session Scope, Page Scope를 통해 전달
- 서버는 최종적으로 HelloServlet의 결과를 응답
- 클라이언트입장에서는 한번의 요청으로 응답을 받음
Web Container 내부에서 서로 다른 서블릿으로 이동할 때 쓰는 개념이다.
Redirect

- 클라이언트가 서버에 요청
- 서버는 상태값 3XX와 함께 Redirect 주소(Location)를 헤더에 보냄
- 클라이언트는 Location 주소값으로 다시 요청
- 서버는 새로운 Resource를 응답
처음 요청한 URL과 리다이렉트가 일어난 후의 URL이 다르게 변경된다.
Web Container로 재요청하게 된다.
즉 요청과 응답이 두번 발생한다.
301 VS 302
301 - Moved Permanently
- 요청한 정보가 새로운 주소로 영구적으로 옮겨갔다는 신호
- 검색엔진은 301 요청을 만나면 컨텐트가 완전히 새로운 URL로 영원히 이동했다고 판단
- 때문에 과거 URL의 페이지 랭킹과 평가점수를 새로운 URL로 이동시킴
- ex) 웹 사이트 도메인 변경이나 새로운 URL 구조로 개편했을 경우
302 - Found
- 요청한 정보가 임시적으로 새로운 주소로 옮겨갔다는 신호
- 검색엔진은 302 요청을 만나면 페이지 랭킹과 평가점수 새로운 URL로 옮기지 않음
- 즉 기존 URL이 보유한 페이지랭킹 점수는 그대로 유지하도록 하면서 컨텐트만 새로운 URL에서 조회하도록 해야할 때 유용
참고자료
3 단계 - 쿠키와 세션
로그인 상태를 유지하기 위해서 쿠키와 세션을 사용한다.
HTTP는 stateless 하기 때문에 세션을 이용해 서버에 해당 유저가 로그인 되었는지를 저장한다.
사이트에 접속하면 각 브라우저마다 고유한 id를 나타내는 JSESSIONID를 발급한다.
요청이 오면 쿠키에서 JSESSIONID를 확인해 없으면 Set-Cookie 헤더를 통해 세션 아이디를 설정하고,
있다면 해당 세션 아이디를 HTTP Sessions 객체에 저장하도록 하였다.
// FrontController#run
if (!request.hasSessionId()) {
response.setCookie(UUID.randomUUID().toString());
}GET /index.html HTTP/1.1
Host: localhost:8080
Connection: keep-alive
Accept: */*
Cookie: yummy_cookie=choco; tasty_cookie=strawberry; JSESSIONID=656cef62-e3c4-40bc-a8df-94732920ed46로그인 시 세션 저장 로직
참고로 요청 객체를 만들 때, Headers 내부에서 쿠키를 따로 파싱해 가지고 있게했다.
// RequestHeaders
public class RequestHeaders {
private static final String DELIMITER = ": ";
private final Map<String, String> headers = new HashMap<>();
private HttpCookie cookie = new HttpCookie();
public void put(String line) {
String[] tokens = line.split(DELIMITER);
if (COOKIE_NAME.equals(tokens[0])) {
this.cookie = HttpCookie.of(tokens[1]);
}
this.headers.put(tokens[0].trim(), tokens[1].trim());
}
// ...
// HttpCookie
public class HttpCookie {
public static final String COOKIE_NAME = "Cookie";
private final Map<String, String> cookies;
public static HttpCookie of(String line) {
Map<String, String> cookieMap = Stream.of(line.split("; "))
.map(x -> x.split("="))
.collect(Collectors.toMap(y -> y[0], y -> y[1]));
return new HttpCookie(cookieMap);
}
public HttpCookie() {
this.cookies = new HashMap<>();
}
public HttpCookie(Map<String, String> cookies) {
this.cookies = cookies;
}
public boolean hasSessionId() {
return this.cookies.containsKey(SESSION_NAME);
}
public String getSessionId() {
return this.cookies.get(SESSION_NAME);
}
}LoginController
@Override
protected void doPost(HttpRequest request, HttpResponse response) {
LOG.debug("HTTP POST Login Request: {}", request.getPath());
try {
User loginUser = userService.login(request);
HttpSession session = request.getSession();
session.setAttribute("user", loginUser);
response.responseRedirect(HTTP + request.getHeader("Host") + "/index.html");
} catch (InvalidLoingInfoException exception) {
response.responseRedirect(HTTP + request.getHeader("Host") + "/401.html");
}
}로그인이 성공하면, 요청 객체에서 session 객체를 꺼내온다.
session 객체를 얻어오는 과정은 다음과 같은데, 현재 서버에 저장되어 있는 세션 아이디가 아닐 경우 세션 아이디를 key, 이로 만들어진 새 HttpSession 객체를 세션맵에 저장해준 후 반환한다.
// Reuqest
public HttpSession getSession() {
return headers.getSession();
}
// RequestHeaders
public HttpSession getSession() {
return HttpSessions.getSession(cookie.getSessionId());
}
// HttpSessions
public static HttpSession getSession(String id) {
HttpSession session = SESSIONS.get(id);
if (Objects.isNull(session)) {
session = new HttpSession(id);
put(session);
return session;
}
return session;
}이렇게 만들어진 session 객체에 setAttribute()를 통해 "user"를 키로 로그인한 해당 유저를 저장한다.
@Override
protected void doGet(HttpRequest request, HttpResponse response) {
LOG.debug("HTTP GET Login Request: {}", request.getPath());
HttpSession session = request.getSession();
if (Objects.nonNull(session.getAttribute("user"))) {
response.responseRedirect(HTTP + request.getHeader("Host") + "/index.html");
return;
}
response.responseOk("/login.html");
}로그인 요청이 오면 먼저 요청에서 session 객체를 꺼내온다.
이 세션 객체에서 user가 있는지 확인하고 존재하는 경우는 이미 로그인에 성공해 user 객체가 저장되있는 경우이므로
index.html로 리다이렉트 시킨다.
[학습 테스트 기록]
입출력(I/O)
- 하나의 시스템에서 다른 시스템으로 데이터를 이동 시킬 때 사용
- 자바는 스트림(Stream)으로부터 I/O를 사용
- 스트림 사용이 끝나면 항상 close() 메서드를 호출하여 스트림을 닫아 누수를 막아야 함
- 자바 9이상부터는 try-with-catch 문으로 자원 해저 처리 가능 - 관련 링크
InputStream
- 다른 매체로부터 바이트로 데이터를 읽을 때 사용
- read()는 기반 메서드
- 서브 클래스(subclass)는 특정 매체에 데이터를 읽기 위해 read() 메서드를 사용
- read() 메서드는 매체로부터 단일 바이트를 읽는데, 0부터 255 사이의 값을 int 타입으로 반환
- int 값을 byte 타입으로 변환하면 -128부터 127 사이의 값으로 변환
- 그리고 Stream 끝에 도달하면 -1 반환
- new String(inputStream.readAllBytes()); 과 같이 String으로 변경 가능
OutputStream
- 다른 매체에 바이트로 데이터를 쓸 때 사용
- 서브 클래스(subclass)는 특정 매체에 데이터를 쓰기 위해 write(int b)메서드를 사용
- FilterOutputStream은 파일로 데이터를 쓸 때, DataOutputStream은 자바의 primitive type data를 다른 매체로 데이터를 쓸 때 사용
- write 메서드는 데이터를 바이트로 출력하기 때문에 비효율적
- write(byte[] data) 와 write(byte b[], int off, int len) 는 1바이트 이상을 한 번에 전송 할 수 있어 훨씬 효율적
- Java OutputStream이란?
ByteArrayOutputStream
- 메모리 바이트 배열에 바이트를 기록
- 버퍼는 데이터가 기록될 때 자동으로 커짐
- 입출력 대상이 메모리이므로 close 하지 않아도 됨
- ByteArrayOutputStream
BufferedOutputStream
- 효율적인 전송을 위해 스트림에서 버퍼링을 사용 할 수 있음
- BufferedOutputStream 필터를 연결하면 버퍼링 가능
- 버퍼링을 사용하면 OutputStream을 사용할 때 flush를 사용하는 것이 좋음
- flush(): 버퍼가 아직 가득 차지 않은 상황에서 강제로 버퍼의 내용을 전송
- Stream은 동기(synchronous)로 동작하기 때문에 버퍼가 찰 때까지 기다리면 데드락(deadlock) 상태가 되기 때문에 flush로 해제해야함
- 큰 파일을 쓸 때 ByteArrayOutputStream보다 유리
- BufferedOutputStream
FilterStream
- InputStream이나 OutputStream에 연결될 수 있음
- 읽거나 쓰는 데이터를 수정할 때 사용
- 필터는 필터 스트림, reader, writer로 나뉨
- 필터는 바이트를 다른 데이터 형식으로 변환 할 때 사용
- reader, writer는 UTF-8, ISO 8859-1 같은 형식으로 인코딩된 텍스트를 처리하는 데 사용
- BufferedInputStream은 데이터 처리 속도를 높이기 위해 데이터를 버퍼에 저장
- InputStream 객체를 생성하고 필터 생성자에 전달하면 필터에 연결됨
- InputStream bufferedInputStream = new BufferedInputStream(inputStream);
InputStreamReader
- 지정된 인코딩에 따라 유니코드 문자로 변환할 수 있음
- 바이트를 문자(char)로 처리하려면 인코딩을 신경 써야 함
- 인코딩을 지정하지 않으면 OS에서 기본으로 사용하는 인코딩을 사용
- BufferedReader를 사용하면 readLine 메서드를 사용해서 문자열(String)을 한 줄 씩 읽어올 수 있음
File
- 웹서버는 사용자가 요청한 html 파일을 제공 할 수 있어야 함
- File 클래스를 사용해서 파일을 읽어오고, 사용자에게 전달
- getClass().getResource()는 호출한 클래스 패키지로 기준한 상대적인(relative) 리소스 경로로 리소스를 탐색
- getClass().getClassLoader().getResource()는 항상 절대적인(absolute) 리소스 경로로 리소스를 탐색
- 하지만 결국 Class.getResource()는 ClassLoader.getResource()에 위임(delegates) 하게됨
- Class.getResource() 와 ClassLoader.getResource()
다음과 같은 방법으로 File을 읽어올 수 있다.
@Test
void 파일의_내용을_읽는다() throws IOException {
final String fileName = "nextstep.txt";
final URL resource = getClass().getClassLoader().getResource(fileName);
assert resource != null;
final Path path = new File(resource.getPath()).toPath();
final List<String> actual = Files.readAllLines(path);
assertThat(actual).containsOnly("nextstep");
}Thread
Concurrency = 병행성
@Test
void testCounterWithConcurrency() throws InterruptedException {
int numberOfThreads = 10;
ExecutorService service = Executors.newFixedThreadPool(10); // 고정된 개수를 가진 쓰레드 풀 생성
CountDownLatch latch = new CountDownLatch(numberOfThreads); // 쓰레드를 N개 실행했을 때, 일정 개수의 쓰레드가 모두 끝날 때 까지 기다려야지만 다음으로 진행할 수 있거나 다른 쓰레드를 실행시킬 수 있는 경우 사용
MyCounter counter = new MyCounter();
for (int i = 0; i < numberOfThreads; i++) {
service.execute(() -> {
counter.increment();
latch.countDown(); // Latch의 숫자가 1개씩 감소
});
}
latch.await(); // Latch의 숫자가 0이 될 때까지 기다림
assertThat(counter.getCount()).isEqualTo(numberOfThreads);
}- FixedThreadPool : 고정된 개수를 가진 쓰레드풀
- MyCounter는 카운트를 세는 임의의 객체
추가로 보면 좋을 글
'우아한테크코스 > 미션 정리' 카테고리의 다른 글
| Level 4. MVC 프레임워크 구현하기 - 정리 (0) | 2021.09.28 |
|---|---|
| Level2. atdd-subway-fare 정리 (0) | 2021.08.06 |
| Level2. atdd-subway-path 정리 (0) | 2021.08.06 |
| Level2. atdd-subway-map 정리 (0) | 2021.08.06 |
| Level2. jwp-chess 정리 (0) | 2021.08.06 |



